分布式计算的替代框架驯服了大数据不断增长的成本
今天,各行各业产生的“大数据”数量之多,甚至开始压倒为筛选所有这些信息而开发的极其有效的计算技术。但是,基于随机抽样的新计算框架似乎最终将驯服大数据不断增长的通信,内存和能源成本,使其更易于管理。
一篇描述该框架的论文发表在《大数据挖掘与分析》杂志上。
近年来,社交网络、商业交易、“物联网”、金融、医疗保健等产生的数据量呈爆炸式增长。这个所谓的大数据时代提供了令人难以置信的统计能力,可以发现模式并提供以前无法想象的见解。但是产生的大数据量开始达到计算极限。
复杂算法的可扩展性在计算机集群或云计算中开始挣扎,大约一TB或一万亿字节的数据。例如,纽约证券交易所每天产生大约500TB的交易数据,而Facebook用户在同一时间内产生<>TB的交易数据。
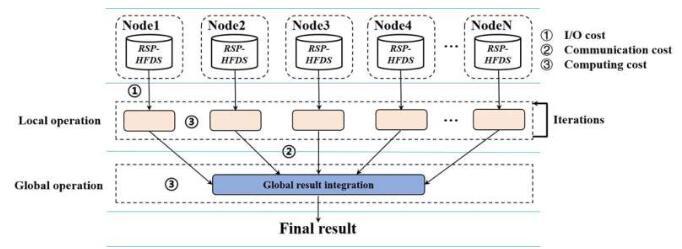
分布式计算在此类大数据的存储、处理和分析中起着至关重要的作用。该框架部署了“分而治之”策略,以高效快速地对其进行分类。这涉及将大数据文件分区为许多称为“数据块文件”的较小文件。
这些数据块以分布式方式存储在计算机群集的许多节点上。然后,这些块中的每一个都并行处理,而不是按顺序处理,从根本上加快了处理时间。然后将这些本地节点的结果反馈到中心位置并重新集成,从而产生全局结果。
这种分而治之的操作又由分布式文件系统管理,而分布式文件系统又由编程模型控制。文件系统是划分大数据文件的东西,编程模型将算法分成几部分,然后可以以分布式方式在数据块上运行。
由Google开发的MapReduce是分布式计算使用最广泛的编程模型,该模型在集群和云上运行。该名称来自其两个基本操作。对节点中的数据块执行映射操作以生成本地结果。这是在多个节点上并行执行的,以实现处理时间的巨大加速。然后,Reduce操作将所有这些局部结果整理成一个全局结果。
后一阶段涉及将本地结果传输到执行Reduce操作的其他主节点或中心节点,所有这些数据洗牌在通信流量和内存方面都非常昂贵。
“这种巨大的通信成本在一定程度上是可控的,”该论文的第一作者、深圳大学计算机科学与软件工程学院的计算机科学家孙旭东说。“如果期望的任务只涉及一对Map和Reduce操作,例如计算一个单词在大量网页上的频率,那么MapReduce可以在数千个节点上非常有效地运行,即使是一个巨大的大数据文件。
“但是,如果所需的任务涉及Map和Reduce对的一系列迭代,那么由于巨大的通信成本以及随之而来的内存和计算成本,MapReduce将变得非常缓慢,”他补充道。
因此,研究人员开发了一种新的分布式计算框架,他们称之为Non-MapReduce,通过降低这些通信和内存成本来提高大数据上集群计算的可扩展性。
为此,它们依赖于一种称为随机样本分区(RSP)的新型数据表示模型。这涉及对大数据文件的分布式数据块进行随机采样,而不是对所有分布式数据块进行处理。分析大数据文件时,随机选择一组RSP数据块进行处理,然后在全局级别进行集成,以产生处理整个数据文件时结果的近似值。
通过这种方式,该技术的工作方式与统计分析大致相同,随机抽样用于描述总体的属性。因此,Non-MapReduce的RSP方法是一种所谓的“近似计算”,这是一种新兴的计算范式,可实现更高的能源效率,仅提供近似而不是精确的结果。
近似计算在计算上成本低廉的大致准确结果足以完成手头任务的情况下很有用,并且优于试图提供完全准确的结果的计算成本高昂的工作。
Non-MapReduce计算框架将为一系列任务带来相当大的好处,例如快速采样多个随机样本以进行集成机器学习;直接在本地随机样本上执行一系列算法,而无需节点之间的数据通信;简化大数据的探索和清理。此外,该框架在云计算中节省了大量能源。
该团队现在希望将他们的Non-MapReduce框架应用于一些主要的大数据平台,并将其用于实际应用程序。最终,他们希望使用它来解决分析分布在多个数据中心的超大数据的应用程序问题。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【首都师范大学是211吗】一、“首都师范大学是211吗”是许多考生和家长在选择大学时经常提出的问题。实际上,...浏览全文>>
-
【首都师范大学科德学院自考和统招毕业证不一样吗有什么不一样的】在选择继续教育方式时,很多学生都会关注“...浏览全文>>
-
【首都师范大学科德学院自考本科国家承认学历吗】一、“首都师范大学科德学院自考本科国家承认学历吗”是许多...浏览全文>>
-
【首都师范大学科德学院怎么样首都师范大学科德学院介绍】首都师范大学科德学院是一所位于北京市的全日制本科...浏览全文>>
-
【第一次电影剧情】《第一次》是一部由美国导演理查德·林克莱特(Richard Linklater)执导的电影,于2004年...浏览全文>>
-
【首都师范大学科德学院学费一年多少钱】首都师范大学科德学院是一所经教育部批准设立的全日制本科独立学院,...浏览全文>>
-
【第一次点外卖的流程】对于第一次尝试点外卖的人来说,整个过程可能会有些陌生。不过,只要按照步骤来,就能...浏览全文>>
-
【首都师范大学科德学院学费为什么要这么贵】首都师范大学科德学院作为一所独立学院,近年来在学费方面引发了...浏览全文>>
-
【第一次登泰山的忌讳】泰山,作为五岳之首,不仅是中国文化的重要象征,也是无数人心中的朝圣之地。对于第一...浏览全文>>
-
【首都师范大学科德学院位于哪个城市】首都师范大学科德学院是一所独立学院,隶属于首都师范大学。对于许多学...浏览全文>>